There is a specific kind of exhaustion that comes from maintaining a Cosmos indexer. It is not the exhaustion of writing hard code. Cosmos data is, by and large, well structured: blocks have heights, transactions have results, messages have type URLs, events have attributes. The exhaustion comes from the fifty small things around the data. The websocket that silently drops at block 342,117 and resumes pretending nothing happened. The public RPC that returns a 502 once every thousand calls and poisons your queue. The authz-wrapped message you forgot to unwrap, so six months of delegations were never indexed for the ten addresses that routed through MsgExec. The synchronous_commit you forgot to turn off, so your Postgres is fsync-bound and you’re indexing at four blocks per second on hardware that could do four hundred. The 487-megabyte genesis that your JSON parser tried to load into memory and killed the container.
We have built several of these over the years. Each one was a little different and all of them were the same. Each time you sit down, the shape of the problem is identical. You need to pull blocks from an RPC as fast as the RPC will let you, demultiplex them into the dozen or so streams of events that matter for your use case, apply them to a schema, survive the day-to-day operational flakiness of both Cosmos RPCs and long-lived Postgres connections, and — because the whole point of indexing is to feed a product — make the resulting database easy to query. You do this, and then someone adds a chain with a slightly different gov module or a homegrown DEX, and you do most of it again.
Eclesia Indexer is the thing we wish we’d had on day one. It is an opinionated, TypeScript, event-driven framework for building Cosmos SDK indexers, structured as four small packages that do exactly one thing each. This post is about how it is put together, what the interesting design decisions were, and why — after years of running Callisto (the Go-based indexer previously known as BDJuno) and a couple of rounds of “just write a script” — we ended up building it the way we did.
What the shape of the problem actually is
Before anything else, a short reminder of what a Cosmos indexer has to do, because the architecture of the framework is mostly a direct response to it.
For every block on the chain, you need:
- The block header and commit (height, time, proposer, validator signatures).
- The block results — the
begin_block,end_block, and per-transaction events, each with typed attributes. - The transactions themselves, decoded from protobuf, including any memo fields.
- For modules that track state (balances, delegations, proposals, vote tallies), the ability to query authoritative chain state at that exact block height via ABCI.
Blocks arrive about once every five to seven seconds on most Cosmos chains. Historical sync means pulling tens of millions of them as fast as the RPC will let you, which on a local node is comfortably over a thousand blocks per second and on a public RPC is whatever the operator feels like giving you. Live sync means staying within one block of the tip without dropping anything, forever.
Everything interesting about the architecture falls out of those constraints.
The monorepo, and why there are four packages and not one
The repository is a pnpm workspace with four packages that stack:
create-eclesia-indexer (CLI scaffolder)
│
▼
@eclesia/indexer-engine (pure engine: fetch, parse, dispatch)
│
▼
@eclesia/basic-pg-indexer (Postgres wrapper: txn, reconnect, height)
│
▼
@eclesia/core-modules-pg (Blocks, Auth, Bank, Staking modules)
The obvious question is why four, not one. The answer is that the engine, the Postgres plumbing, and the domain modules change at completely different rates and for completely different reasons. The engine has a narrow surface — fetch blocks, run modules over them, survive RPC weirdness. It should be stable for months at a time. The Postgres layer is where we make opinionated choices (raw SQL, manual recycling, synchronous_commit = OFF) that a large subset of users will want to override. The modules are the ones that actually churn as chains fork new gov variants, new tokenomics, new denoms. Bundling them together means every time the Cosmos Hub updates x/gov, every user has to bump their engine version. Splitting them means the engine stays boring on purpose.
We’ll walk through each package in the order that data flows through them.
The engine: fetch, buffer, dispatch
@eclesia/indexer-engine is the heart of the framework. If you only read one file in the repo, read packages/indexer-engine/src/indexer/index.ts. It is about 1,200 lines of TypeScript and contains almost all of the interesting decisions.
The engine is structured as two coroutines connected by a bounded queue. The fetcher, in fetcher(), sits on the RPC and pulls blocks as fast as it can. The processor, in start(), dequeues blocks one at a time, opens a database transaction, fans the data out to registered listeners, and commits. If any listener throws, the transaction is rolled back and the whole engine enters a bounded retry loop.
What makes it non-trivial is the queue between them.
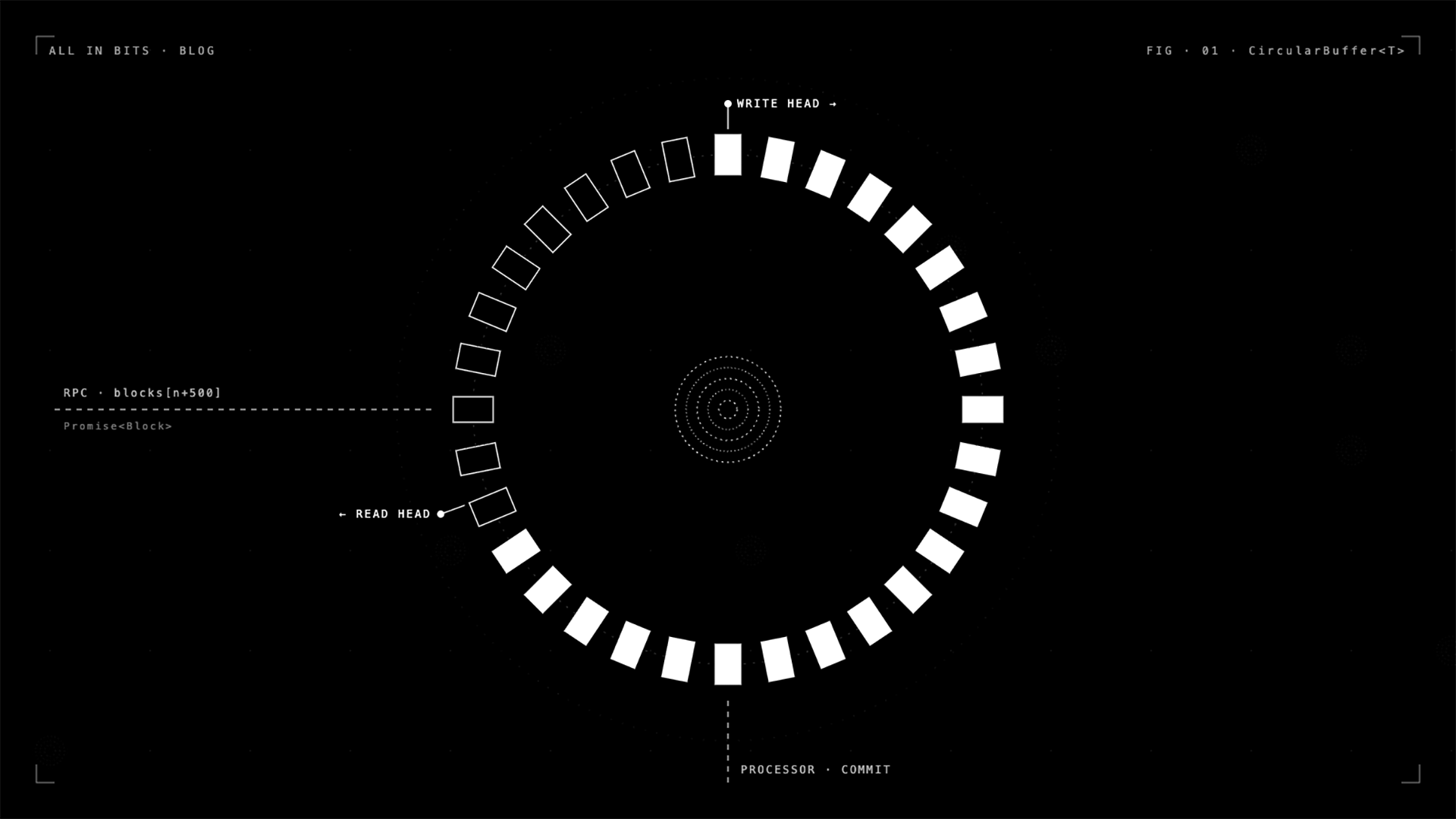
The circular promise buffer
The queue is a CircularBuffer<T> living in packages/indexer-engine/src/promise-queue/index.ts. It is small, about 140 lines, and deliberately weird.
A naive Node.js implementation would be a plain array — push when the fetcher has a block, shift when the processor wants one, and await some event emitter in between. That works at low throughput and falls over the moment you have 500 blocks in flight, because every shift reallocates, the GC thrashes, and your backpressure logic has to be written by hand with semaphores or ugly while (queue.length > max) await new Promise(...) spin loops.
The CircularBuffer is a fixed-size ring of slots, each holding a Promise<T> rather than a resolved value. The fetcher does not push blocks; it pushes promises of blocks, and fires off the RPC call in the background without awaiting it. The processor dequeues by awaiting the promise in the next slot. Two pointers, next and nextAvail, track read and write heads, wrapping with modulo arithmetic. A count tracks how many slots are unconsumed, and continue() returns a promise that resolves only when count <= batchSize, so fetchers stall promise-style instead of busy-looping. No allocations after startup. No shifted arrays. Fixed memory regardless of how many blocks have flowed through.
The effect is that the fetcher can dispatch, say, 500 concurrent RPC calls, each racing against a 20-second timeout (RPC_TIMEOUT_MS), without the processor ever having to know or care about parallelism. Each dequeue simply awaits the next promise, and if the RPC hasn’t answered yet, the processor blocks there — exactly as you want.
This also gives you, almost for free, the property that blocks are delivered to the processor in strict height order even though their RPC responses arrived out of order. The slot at index n will only resolve when its specific promise resolves, and the processor awaits slots in index order. Out-of-order completion doesn’t leak into out-of-order processing.
Two RPC clients, not one
A detail that took us longer than it should have to get right: the fetcher holds two CometBFT clients, not one. One is used exclusively for block and validator queries (the sequential hot path). The other is used for ad-hoc ABCI calls from modules (things like QueryAllBalancesRequest at a specific height).
The reason is head-of-line blocking. CometBFT clients serialize requests over a single websocket. If a module fires an ABCI call that takes 400ms, every block fetch queued behind it waits. Two clients means module queries and block fetches never compete for the same socket. It is the kind of fix you only make after you stare at a flame graph for an hour wondering why your p99 block processing time is eight times the p50.
Genesis streaming, which is its own project
Genesis files on mainnet chains are not small. AtomOne’s is 487 MB and contains 1.1 million accounts. Cosmos Hub’s is similar. Loading one of these with JSON.parse requires a heap larger than the file, which on default Node settings simply OOMs.
The engine pipes genesis through stream-chain and stream-json with configurable picklers. For each path the user cares about (app_state.auth.accounts, app_state.bank.balances, and so on), a module registers either an “array reader” or a “value reader”. The array reader batches entries in groups of 1,000 and emits them as a single event per batch, while committing the database transaction every 5,000 entries to avoid the long-lived WAL that would otherwise grind Postgres to a halt on a one-million-account import. The value reader is for the singletons — gov params, staking params — that don’t need batching.
The one genuinely clever part is how it handles gentxs. Cosmos genesis files ship with validator creation transactions inside app_state.genutil.gen_txs. Each gentx contains an arbitrary list of messages. The engine unpacks each one and re-emits it as gentx/<typeUrl>, so a module that handles MsgCreateValidator just registers one listener and gets both the genesis-time creations and the runtime-time ones. The staking module uses exactly this pattern at packages/core-modules/src/cosmos.staking.v1beta1/index.ts to seed the initial validator set.
Event dispatch, with UUIDs and error rollback
The dispatch layer is the other non-obvious piece. It is called EclesiaEmitter and it wraps Node’s native EventEmitter with one interesting property: asyncEmit(type, event) does not return until every registered listener has finished handling the event, and rejects if any of them throws.
The implementation injects a UUID into every emitted event. Each listener is wrapped in an async context that, on completion or error, emits a response event keyed on that UUID. asyncEmit counts listeners before dispatch, then awaits exactly that many responses. A failure in any listener short-circuits the whole thing with an error.
This matters because the engine wraps every block in a database transaction. beginTransaction() fires before any events for the block are emitted, and endTransaction(success) fires after asyncEmit resolves, committing on success and rolling back on failure. If the bank module’s write fails halfway through processing block 1,234,567, the staking module’s writes for the same block get rolled back too, and on the next retry the processor re-dequeues and re-emits — exactly once, atomically.
The event types themselves are a flat namespace of strings: "block", "begin_block", "end_block", "tx_events", "tx_memo", and for each decoded transaction message the fully-qualified type URL ("/cosmos.bank.v1beta1.MsgSend", "/atomone.gov.v1.MsgSubmitProposal", etc.). There are also three periodic events — "periodic/small", "periodic/medium", and "periodic/large" — that fire every 50, 100, and 1,000 blocks respectively, so modules can do batched aggregation without writing cron logic.
One subtlety we are proud of: the engine unwraps MsgExec automatically. A lot of Cosmos activity routes through authz, and an authz-wrapped MsgSend is still a send, even though the outer type URL is /cosmos.authz.v1beta1.MsgExec. The engine decodes the inner messages and re-emits each with its own type URL, tagging the event with an authz_msg_index so modules can distinguish direct from wrapped calls if they need to. Every naive Cosmos indexer we have seen has missed this, including the first ones we wrote ourselves. Baking it into the framework means nobody has to rediscover it.
Recovery, and what it does not do
The engine has bounded retry logic: on error, it reconnects both RPC clients, waits retryCount * 5000 ms, and re-enters start(). After three failures it emits a "fatal-error" event and lets the wrapper decide whether to exit. There is a 30-second inactivity timeout on the websocket subscription, so if a chain halts or the connection silently dies, the engine notices and recovers.
There is no in-engine reorg handling. This is deliberate. Cosmos reorgs are extraordinarily rare in practice (BFT finality), and when they happen, the correct response is domain-specific: do you roll back the last N blocks? Do you snapshot and replay? Do you alert and pause? The engine exposes a getNextHeight() callback so the wrapper can return any height it likes, including “go back five blocks because I detected a hash mismatch”. It does not try to make that decision for you.
Observability is Prometheus, served on port 9090, plus a separate Fastify health endpoint on 8888. The metric we reach for most often is indexer_queue_depth: if it sits at zero for long stretches during historical sync, your RPC is the bottleneck; if it sits at batchSize, your database is.
The Postgres wrapper: thin on purpose
@eclesia/basic-pg-indexer is, genuinely, one file. It is packages/basic-indexer-pg/src/index.ts, about 320 lines, and its only job is to wire the engine’s transaction callbacks to a raw pg.Client.
There is no ORM. There is no query builder. There is no migration framework. These are choices, and they are not the right choices for every project, so it is worth explaining them.
The wrapper’s beginTransaction calls this.db.query("BEGIN"). endTransaction(true) calls COMMIT. On commit, a counter increments, and when it crosses DB_CLIENT_RECYCLE_COUNT (currently 1,500), the client is disconnected and reconnected from scratch. This sounds paranoid and it is, but long-lived pg.Client connections genuinely degrade — you get memory creep in the driver, occasional prepared-statement cache issues on some Postgres versions, and worst of all, a failure mode where the connection silently half-closes and every subsequent query hangs until the TCP keepalive times out ten minutes later. The recycle is a cheap insurance policy and the cost is negligible because it only fires every few minutes in steady state.
The wrapper sets synchronous_commit = OFF on every fresh connection. This is the single most impactful performance knob in the entire framework. With it on, every commit waits for fsync. With it off, commits return as soon as the WAL buffer is written, and fsync happens asynchronously. On historical sync this is the difference between ~50 blocks per second and ~500 blocks per second on the same hardware. The tradeoff is that if the database process crashes before the WAL is flushed, you may lose the last few transactions. For an indexer, that is fine — you just resume from getNextHeight() and reindex the missing blocks. The chain is the source of truth, and the indexer is reconstructable.
getNextHeight() is a one-liner: SELECT * FROM blocks ORDER BY height DESC LIMIT 1. It runs once at startup and once after every retry, and that is it. There is no height cache, no checkpoint table, no separate metadata store. The blocks table is the checkpoint.
Modules are handed the PgIndexer instance in their init() method and do their own raw SQL. They own their schema. setup() on each module is expected to be idempotent DDL — typically it reads a .sql file from disk and runs it inside a transaction, guarded by an IF NOT EXISTS or a pg_tables check. This is the part of the framework that is least like a framework, and some users will find it uncomfortable. We did not want to build a schema-management system because a good one is a multi-year project (see sqitch, flyway, prisma migrate) and a bad one is worse than nothing. Raw SQL with a setup() hook is the minimum viable contract, and it leaves users free to use whatever migration tool they already like.
The core modules, and the shape of a module
@eclesia/core-modules-pg ships four modules. All of them implement the same interface, in @eclesia/indexer-engine types:
export interface IndexingModule {
indexer: EcleciaIndexer
name: string
depends: string[]
provides: string[]
setup: () => Promise<void>
init: (...args: any[]) => void
}
depends and provides are informational. The engine does not topologically sort them. Users compose the array of modules themselves when constructing PgIndexer, and the implicit dependency order is the array order. This is another “small, not clever” decision — a DAG-based loader sounds nice until you realize most users have five modules and know what order they go in.
The four built-in modules are:
Blocks.MinimalBlocksModuleandBlocks.FullBlocksModule. The minimal one writes height and time into ablockstable and nothing else. The full one decodes every transaction, stores the tx hash, messages, gas used, and maintains three rolling average-block-time metrics (per-minute, per-hour, per-day) using upsert-into-single-row tables. Almost every project wants one or the other.AuthModule(cosmos.auth.v1beta1). Maintains a singleaccountstable keyed by bech32 address. Seeds it from the genesisaccountsarray, and at block 1 explicitly queries each of the standard module accounts (fee_collector,mint,bonded_tokens_pool,not_bonded_tokens_pool, and so on) via ABCI. Every other module that needs an account foreign key references this table.BankModule(cosmos.bank.v1beta1). Tracks balances per address per height. Uses a custom Postgres composite type,COIN(denom text, amount text), and stores balances asCOIN[]arrays so a single row captures an address’s full multi-denom portfolio at a given height. On events, it parsescoin_spent,coin_received,burn, andcoinbase, decodes the base64-encoded attributes, does BigInt arithmetic (never floats, neverNumber), and writes a new row. Historical balance queries becomeWHERE address = $1 AND height <= $2 ORDER BY height DESC LIMIT 1.StakingModule(cosmos.staking.v1beta1). The largest of the four at about 1,100 lines. Models validators, delegations, redelegations, commissions, descriptions, voting powers, and status transitions. Each mutable field is versioned by block height, so you can ask “who was jailed at block 5,000,000?” and get a correct answer. Two LRU caches (operator-to-consensus address mapping, and validator current state) keep per-block processing fast during message-heavy blocks. The share-to-token math usesbignumber.jsbecause Cosmos delegator shares are fractional and subtle and losing three digits at the tail of a calculation will make your staking totals drift over time.
All four load their schema from SQL files under src/<module>/sql/*.sql. Addresses are bech32, amounts are strings, heights are bigints, and nothing is ever a JavaScript Number. These sound like obvious rules and they are also the ones every new Cosmos indexer gets wrong.
A real example: the AtomOne indexer
AtomOne Indexer is a working production indexer for the AtomOne chain, built on the framework. It is the honest test: how much code do you write to index a real Cosmos chain?
The entire bootstrap is 64 lines. It imports the four core modules, imports a custom GovModule for AtomOne’s governance variant, constructs a PgIndexerConfig from environment variables, and starts. The entire “extend the framework” surface is 727 lines of src/modules/atomone.gov.v1beta1/index.ts plus about 100 lines of SQL, covering the full governance lifecycle: proposals (v1 and v1beta1), deposits, votes (including weighted), tally results, and per-proposal snapshots of staking pool state and validator voting power.
The pattern inside GovModule is what makes this tolerable:
this.indexer.on("/atomone.gov.v1beta1.MsgSubmitProposal", async (event) => {
const prop = MsgSubmitProposal.decode(event.value.tx);
const propResp = await this.indexer.callABCI(
"/atomone.gov.v1beta1.Query/Proposal", propReq, event.height
);
await this.saveProposal(/* ... */);
});
Decode the message, ABCI-query the authoritative state at exactly the right height, write it to the database inside the block’s transaction. No race conditions, no “eventually consistent” caveats, no reconciler jobs. The reason this works is the engine’s transactional semantics: if the ABCI call fails, the whole block rolls back and gets retried.
The docker-compose for the project bundles Postgres 15 tuned for indexing (work_mem=2048MB, max_wal_size=4GB, synchronous_commit=off), the indexer itself, and Hasura 2.38. The Hasura metadata exposes 25 tables as GraphQL types with relationships automatically traversable: proposals nest their votes, votes nest their voter accounts, accounts nest their balances. No REST endpoints were written. Nobody on the team built a query API. They declared foreign keys correctly and Hasura did the rest.
This is the example we keep pointing at when people ask whether it is worth it. A full indexer — genesis-aware, governance-complete, with a production GraphQL API — in about 800 lines of project-specific code. The rest is the framework.
The CLI, or why you should not write your own bootstrap
create-eclesia-indexer is create-react-app for this ecosystem. npx create-eclesia-indexer@latest walks you through two waves of prompts — project name, chain prefix, RPC endpoint, genesis path, which modules to include, package manager, log level — and produces a working project with:
- An
src/index.tswired up to exactly the modules you selected. - A
docker-compose.ymlwith Postgres, the indexer, and Hasura. - A
Dockerfileselected for your package manager (pnpm/npm/yarn), using multi-stage Alpine builds. - A
tsdown.config.tsthat produces ESM and CJS with.d.tsand sourcemaps. - An
eslint.config.mjsthat is strict enough to catch real bugs and lenient enough not to fight you. - A
.env.templatewith every knob documented.
The clever bit is how it generates the src/index.ts. Based on your answers, three helper functions (generateModulesImport, generateModulesInstantiation, generateModulesArray) write the import statement, the module constructors, and the array literal. If you said “no genesis, start from a recent height”, it omits the bank module and switches blocks to minimal. If you said “full, genesis, from block 1”, you get all four with staking enabled. This is the kind of thing you only notice when it is missing, which is always, because nobody ever writes this for their own scaffolders.
The generated project has local-dev:start, docker:build, build, dev, lint, and start scripts. Running npm run local-dev:start from zero to indexing-in-progress is about three minutes on a reasonable machine, most of which is Docker pulling images.
The honest part: what it doesn’t do
We want to be up front about this, because every framework README lies about this section.
There is no chain reorganization handling. This is deliberate, and the wrapper’s getNextHeight is the escape hatch, but it means you have to think about reorg semantics if your chain actually has them. In practice, Cosmos chains don’t, but if yours does, this framework will not save you from yourself.
There is no distributed indexing. One engine instance, one RPC endpoint, one database. If your chain produces more data than a single node can ingest — which, realistically, no Cosmos chain does today — you need a different tool.
There is no built-in REST or GraphQL API layer. You get Hasura via the scaffold, which is the right answer for 90% of projects, but the engine itself does not serve queries. This is correct: indexers write, APIs read, and mixing them produces worse systems.
There is no automatic schema migration. You own your DDL. If you rename a column in a module, you write the ALTER TABLE. The upside is total control and zero abstraction tax. The downside is that large deployments will want to layer a migration tool on top.
There is no ORM. This is a hill we will die on. ORMs for indexing workloads are a net negative: they hide the N+1 queries that will actually destroy your throughput, they make bulk upserts awkward, and they encourage you to model “an account” as an object rather than as a set of rows versioned by height. Raw SQL is uncomfortable for three days and excellent for three years.
How this relates to the work that came before
The most direct ancestor of this project is Callisto — the Go-based indexer written by Forbole, previously known as BDJuno and originally as BigDipper for Juno. Callisto still powers most Cosmos block explorers in production today. We have run it and its predecessors for years, and a lot of what is in eclesia-indexer-core is a direct response to that experience.
The single biggest debt we owe Callisto is the module idea itself. The notion that a Cosmos indexer is fundamentally a collection of per-x/module handlers, each owning its own subscriptions and tables, came from reading how Callisto was structured. Without that, we would probably have ended up with yet another monolithic ingestion script. The modular architecture of eclesia-indexer-core — IndexingModule as a first-class interface, setup() per module, the whole depends/provides surface — is Callisto’s idea, redone in TypeScript with stricter isolation.
The places where we diverged are the places where, running Callisto in anger, we wanted something different:
- We wanted each module to fully own its schema, including its DDL file, so that shipping a new module into a production deployment never required coordinating with upstream or touching any other module’s tables.
- We wanted genesis streaming to be a first-class operation rather than something you worked around on large chains, because we had lost enough hours to OOMs on multi-hundred-megabyte genesis files.
- We wanted transactional per-block semantics where any module failing rolls back the entire block atomically, so partial writes never leak into the database.
- We wanted the whole stack in TypeScript, because the rest of what our team ships — frontends, APIs, dev tools — is in TypeScript, and the friction of context-switching between the indexer language and the product language was higher than we wanted to keep paying.
None of this is a criticism of Callisto. It is a production-grade piece of software that has served the Cosmos ecosystem well for years, and our framework exists in the shape it does in part because Callisto showed us what a module-per-Cosmos-module indexer could look like. eclesia-indexer-core is what happens when you take that idea, give each module its own schema boundary, and rebuild the plumbing underneath in a language your team already lives in.
There are, of course, other options in the landscape. Hosted TypeScript indexing via SubQuery. The Graph’s Cosmos subgraph runtime. The omnipresent “just write a script” pattern that dominates first attempts. We have not run any of those in production, so we won’t make claims about them. If one of them fits your team better than what we describe here, use it. The problem eclesia-indexer-core is trying to solve is specifically: self-hosted, TypeScript-first, module-per-schema, opinionated about the hard parts (backpressure, transactions, connection recycling, genesis streaming, authz unwrapping) and unopinionated about the easy ones (your schema, your migrations, your API).
The development journey, briefly
The first version of this was a 400-line script. It got promoted into a package the day we needed two copies of it for two different chains and caught ourselves about to diff them. The circular buffer came from a week-long investigation into why a naive Array.shift-based queue was spending 30% of CPU in GC during historical sync. The two-RPC-client split came from a flame graph. The DB_CLIENT_RECYCLE_COUNT = 1500 came from a production incident where a connection half-closed and the indexer sat wedged for six hours overnight. The synchronous_commit = OFF came from benchmarking. The authz unwrap came from a user asking why their delegator list was wrong.
None of those decisions are clever individually. Each one is the obvious fix you make after the problem has happened to you. The point of building a framework is so the problems do not have to happen to anyone else.
The thing we are most pleased with is what the framework does not contain. There is no plugin system for the plugin system. There is no dynamic module reload. There is no runtime configuration DSL. Every choice the framework makes is a choice you have to make eventually anyway, and baking them in where they belong means the surface area of the thing you have to understand to use it is small. Read the engine’s indexer/index.ts, read the wrapper’s index.ts, read one module’s 400 lines, and you have read the entire system. That was the target from the beginning, and the fact that it has held up across multiple production deployments is the part we quietly measure success by.
If you are about to start writing a Cosmos indexer, you do not have to use this framework. We would, of course, prefer that you did. But even if you do not, please at least steal the ideas: the module-per-schema boundary (credit to Callisto), the bounded promise buffer, the two-client split, the periodic events, the authz unwrap, the connection recycle, the streaming genesis, the raw SQL per module. These are not opinions. They are the set of things that every production Cosmos indexer ends up doing, and any framework or script that does not do them is going to end up doing them eventually, in production, at three in the morning.
The repo is at github.com/allinbits/eclesia-indexer-core. The AtomOne example is at github.com/allinbits/atomone-indexer. If you build something on top of it, tell us. If you break it, tell us faster.